How do you know what "Risks" you are shipping with your product ?
I am an experienced Vulnerability Researcher and Security Architect with 16+ years of experience in various verticals and horizontals, be it consumer electronics, semiconductors, automotive or other. Having started in software engineer in low-level embedded devices from writing applications to kernel drivers on various operating systems and then moving to my real calling i.e. hacking. Love to stick to the older golden days of game hacking, BBS, shareware, phreaking, phrack, virus era, metal music, cheats and many more such cool stuff from the underground. I wear many hats from time to time as necessary - but I also love to help people and organizations to deal with the core cybersecurity issues and not provide them a checklist with a presentation. Opinions and posts on my site are purely my own and do not reflect my work.
Story Time Phreaks !
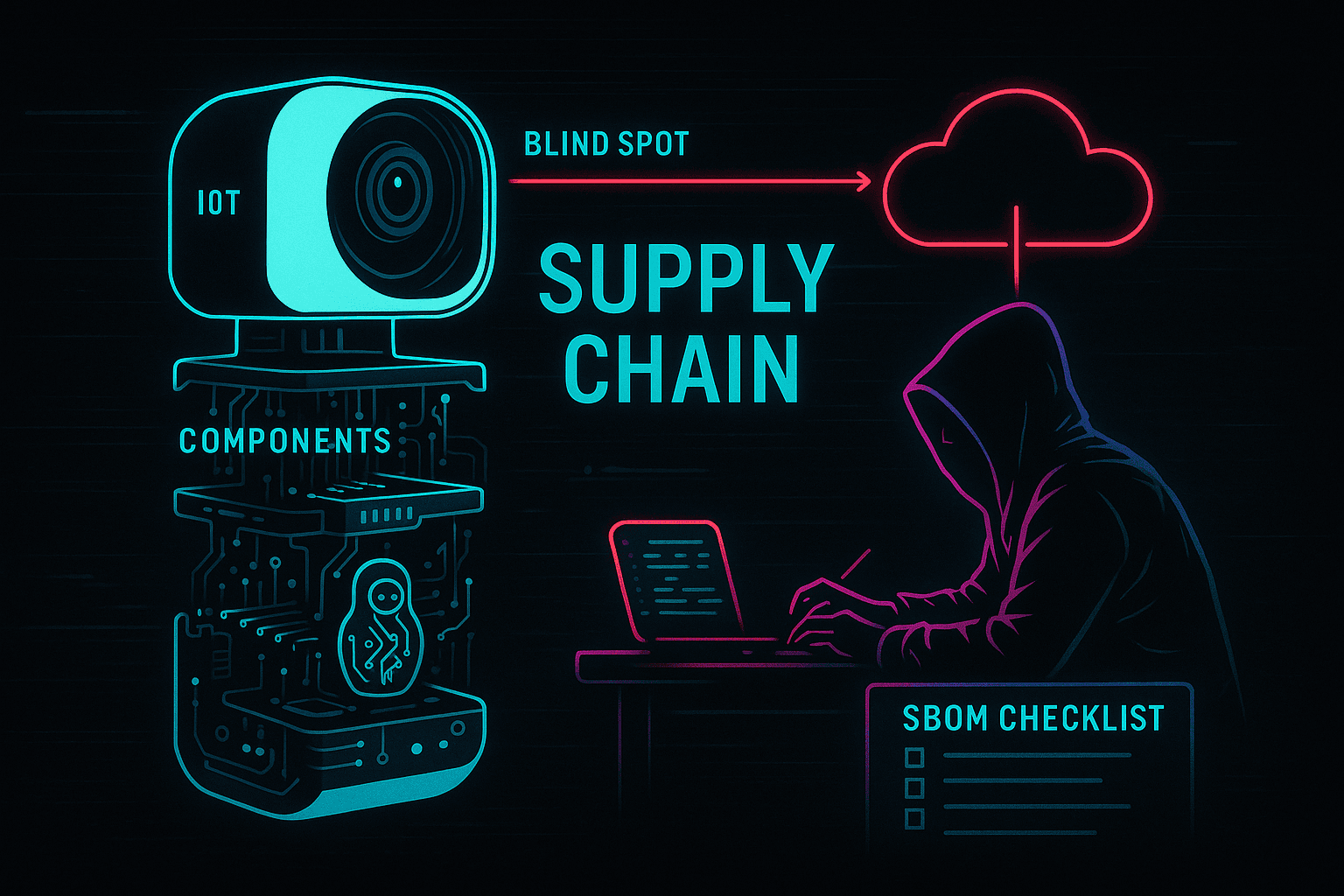
You scroll Amazon or AliExpress late at night and a shiny IP or door camera shows up. It promises WiFi, Bluetooth, a slick app, cloud view, maybe even some AI sticker on the box. The price feels like a win so you buy it. What you do not see is the rest of the picture. The same camera can quietly invite strangers into your living room. Not because you are careless, but because the device is a patchwork of other people’s code and choices shipped fast. E.g. here and here and countless more - do you need a dashboard ?
Risk sneaks in two ways. Sometimes it is intentional and the design serves a purpose that is not yours. More often it is accidental. Normal companies under normal pressure assemble products the way everyone builds now. Layers of chips, SDKs, open source libraries, vendor firmware, and cloud glue that a contractor grabbed on a Tuesday. No one writes a fresh TLS stack. No one invents a new JSON parser. You pick parts that seem reliable, wire them together, demo the feature, and close the ticket. That is what velocity looks like.
Provenance is what gets lost. Your team buys a module from Company A. That module bundles firmware from Supplier B. Supplier B links a library from C. The library depends on a blob from D that has not seen an update in years. By the time the product ships, the box in your hand is a matryoshka of strangers’ code. If you cannot name it, you cannot patch it. That unknown middle is the supply chain blind spot. It is the difference between hotfixing tonight and discovering your camera speaks a language you do not.
Picture this. A small vendor lands a purchase order for ten thousand connected devices for a transport fleet. The team celebrates. Boxes leave the warehouse. Dashboards light up. Someone posts photos of pallets on LinkedIn. Local press covers the story. A reseller promotes it on the homepage. The attention feeds sales and it also feeds curiosity. Somewhere else, someone (i hope its not someone like fisher or you are royally fucked bruhh) orders two of those devices with the same one click checkout. There are no NDAs and no introductions. They are not a customer in the usual sense. They keep a clean bench for new hardware.
On the bench the device opens like any other. The case comes off. The board gets photographed. Flash is dumped. The firmware slides into familiar tools. Strings spill. File systems unfold. Symbols line up. The mobile app is unzipped so the traffic model is visible. Cloud endpoints are listed and filed. Within a day, and sometimes within an afternoon, an old and unfixed issue appears. It is not a zero day. It is a known problem in a third party component the vendor did not realize they shipped. A public proof of concept already exists. It is not elegant. It is enough.
From there the work moves quickly. Remote code execution lands on the device. Secrets fall out with it. Tokens that let the device prove itself to the backend. Keys that authorize uploads. With those in hand the attacker does not kick in a cloud door. They walk in as the device they just compromised. The map expands. Bucket names. Topics. Internal dashboards that were never meant for the public internet. Nothing dramatic, only predictable. They take what proves the point. They write a careful post. They publish code that makes the issue reproducible. If they are responsible it appears after a disclosure clock. If they are not it appears without warning.
The vendor’s incident channel lights up. Logs are pulled. The first reaction is confusion. The exploit never touches the code the team remembers writing. It never calls the APIs they swear they locked down. It slices through a different layer that arrived pre assembled inside a radio module, or a vendor SDK, or a small helper binary that never made the architecture slide. The fix is not obvious because the broken piece is not really theirs. Emails go out. Can Supplier B confirm the version. Can Company A share a build. Can anyone find the engineer who integrated this. Is the original vendor still in business. Does anyone have the source.
This is the moment where theory becomes heavy. Upstream is slow because upstream is busy or gone. The vulnerability is only real to them after you reproduce it on your exact build with your exact flags. The component you need to update depends on a compiler no one has installed in years. Secure boot is only partially secure. OTA is only partially over the air. Rollback is a shrug. Even if everything lines up, swapping a library changes the memory layout and breaks a driver that saw one test on a Friday afternoon. Rebuilding a thing you did not assemble feels like surgery without a chart.
It sounds bleak, and it is honest. The goal is not to dunk on teams that ship devices. The goal is to accept that risk is baked into how we build. The answer is not perfect code. The answer is traceability and rehearsal. Know what is in the box that carries your logo. Not a marketing SBOM. A real one. Hashes of the actual blobs that reach the flash. Know which parts by exact version speak to the outside world. Name the update agent. Name the P2P relay. Name the tiny web server that everyone forgets until it turns into root. If a stranger on the internet drops a working exploit for one of those pieces tomorrow, you should be able to say, without guessing, whether you shipped it.
Practice the hard part next. Patching for real. An emergency update drilled end to end, including failure paths. If a fix lands at ten at night, you should be able to stage it to one percent of units, watch telemetry, hold a rollback switch, and ramp the release. You should be able to push a hotfix without bricking boxes that live in trucks and talk over weak networks. You should be able to do it again two days later if the upstream patch introduces a regression. You do not find those answers in a sprint board. You find them in dry runs, alarms, and quiet postmortems.
All of this looks expensive until you compare it to the bill you pay when things go wrong. The cost of a recall is not just shipping and swaps. It is days of engineering calendars set on fire. It is strained contracts and nervous customers. It is a permanent search result that ties your name to unauthorized access. The cost of refusing to look is higher than the cost of learning to see.
Here is a short questionnaire to turn the story into a concrete self check. Keep the voice, keep the pace, but get the answers in writing.
Questions to ask yourself
Do we have a real firmware SBOM with exact versions and hashes for every binary and library
Can we name the update agent, the tiny web server, the P2P or relay SDK, and the crypto library by version
Which components initiate outbound connections, to which domains, and with what trust roots
Are device secrets unique per unit and stored in hardware or an equivalent protected store
Did we remove default creds, debug interfaces, and unauth endpoints from production images
Can we stage an emergency OTA to a small slice, observe telemetry, roll back safely, and ramp within forty eight hours
Are updates signed, anti rollback enforced, and recovery reliable under power loss and weak networks
Can we rebuild and patch third party components we did not write, including toolchains and licenses
Do we track first hop suppliers for every module and have named contacts who answer
Do contracts require upstream SBOMs and specify CVE response time with a security advisory channel
Which parts of our stack are end of life, and what is our swap or containment plan now, not later
If a third party SDK or proxy fails, could any user ever see another user’s data
Can we rotate device credentials fleet wide without touching hardware
If someone drops a proof of concept tonight, can we answer are we affected with evidence in under two hours
The camera you bought in two clicks is not the villain. The villain is the gap between the product you think you shipped and the stack you actually shipped. Attackers live in that gap because everyone moves slowly there. Closing it is not glamorous. It is build sheets and pinned versions. It is upstream contacts who answer when it is late. It is tests that run on the whole device, not just the UI. It is a habit of treating what is inside as a first class question, not an audit note.
Ghost Conclusion
You do not need perfect code to ship a safe product. You need a product you can name, prove, and repair. If you can list the ingredients you can track the risks. If you can track the risks you can patch without panic. The day your success post goes a little too viral someone will put your device on a bench. That is not paranoia. That is how this industry moves. The difference between a headline and a footnote is your ability to say, with a straight face, that you know what you shipped and that you can fix it.
Note: Images are AI generated.
For professional queries and projects, reach out to me at abhijit.lamsoge@outlook.com



